
Technical Documentation
Technical Documentation
For customers requiring access to bulk property and owner data for aggregations, analytics, or integration with existing data (proprietary or public), bulk data feeds provide an easy way to obtain the data you need for offline use. Our data pipeline runs weekly, ensuring we always have the most recent property data available. Once your job is configured, we can schedule it to deliver refreshed data on whatever cadence suits you (weekly, monthly, quarterly, etc.).
Bulk data feeds are available to enterprise customers only. For information about becoming a Reonomy enterprise data customer, email us at sales@reonomy.com.
The interactive simulation below demonstrates the basic steps to creating and using a bulk data feed. It shows only a few of the over 70 available search settings and a small fraction of the over 400 available data attributes, but it illustrates the key concepts of defining properties of interest, specifying the data attributes you want, running the job, and retrieving the output file.
Real bulk data feed jobs run asynchronously, meaning jobs are queued and run based on availability of backend resources. Jobs may take up to 12 hours to complete, but you can generally expect results in 1-2 hours. You'll receive an email notification when the output is available.
The results of the simulated run below are displayed as a CSV file, but we can also deliver NDJSON. You can schedule your job to run automatically (for example, weekly or monthly), and you have the option to receive only records that have changed since the last run.
We offer two approaches:
Reonomy charges for data based on a set of criteria that includes:
For more information, email us at sales@reonomy.com.
Defining a bulk data feed is a 3-step process you'll go through with your Reonomy Customer Success Manager, or with the help of the Solutions team:
Reonomy provides two distinct ways to identify properties of interest:
We provide an extensive range of search parameters for creating targeted searches that return a very specific set of properties. See the full list of search parameters on the right.
The interactive simulation below provides a simplified view of the four basic steps for a match job. It illustrates the key concepts of identifying properties using location information (addresses in this case, but could be geo-locations), specifying the data you want, running the job, and retrieving the resulting output file.
The row_id works as a common field you can use to "join" the results to your source data. In the example, the address 2602 E 9TH ST in the input file maps to the industrial property with ID 036e0d39... in the output file, etc.
Once you've identified the properties you're interested in, we need to know:
Individual attribute selection is only available for CSV output. With NDJSON, you can select which categories to include (sales, mortgages, etc.), but can't select individual attributes within those categories. Use the interactive attribute tree below to explore the available attributes in each category.
We offer two output file formats, illustrated on the right:
\n) character between each object. NDJSON provides a complete nested representation of all the available data for the selected properties and the selected detail types.sales, taxes, etc.), you must specify how many list items to include. Flat file conversion is described below. When you select CSV as the output format, the bulk data feed file assembly component must transform the nested data schema into a flat file representation. This requires that you select which of the available attributes you'd like to include in the output file. Additionally, for lists (for example, mortgages, taxes, etc. as well as some nested attributes), you must specify how many list items to include (5 is typical). We require this to control the width of the resulting CSV file (see the example on the right).
The interactive example below illustrates how we convert a nested hierarchy into a flat file. Click attributes in the nested representation to see how the columns in the resulting CSV file will look. Use the slider to see how changing the list item count affects the number of output columns (the property_id column is not included in the count).
If you select an attribute within a nested detail type like contacts, the List item count slider below lets you see how the number of CSV columns increases exponentially as you increase the list item count. For example, if you select contacts[n].persons[n].addresses[n].city with the list item count set to 3, this results in 3 x 3 x 3 = 27 columns, while setting it to 6 yields 216 columns.
Properties:
List item count:
Attribute count:
| property_id |
|---|
| <property_id> |
With the default output format, property data is returned as one-record-per-property within a single file. Because each record represents a single property, we call these property-centric reports.
As an alternative, we offer multi-file output, where the data for each selected detail type (mortgages, taxes, etc.) is returned as a separate file. Within each file, each constituent record (mortgage document, tax record, etc.) is returned as a separate NDJSON record or row in the CSV file. We call these entity-centric reports.
The interactive example below illustrates the difference between single file (property centric) and multi file (entity centric) output:
property_id is included with each record, so you always know which property the record belongs with.When the single file option is selected, foreclosure information is not available. With multi file, foreclosure information is available as a separate detail type.
foreclosure is not a valid detail type with single file output, the foreclosure switch is not shown below. Properties:
List item count:
Attribute count:
Our data pipeline runs weekly to integrate the latest updates from our many data providers. This ensures we always deliver the most recent property data available.
Since bulk data feeds output files are decoupled from our data pipeline, we provide a scheduling mechanism to run your job automatically and deliver new output files. This enables you to refresh your downstream applications and data models with the latest updates on whatever cadence suits you (weekly, monthly, quarterly, etc.). When new output files are ready, we send automated email notifications letting you know they are available to download.
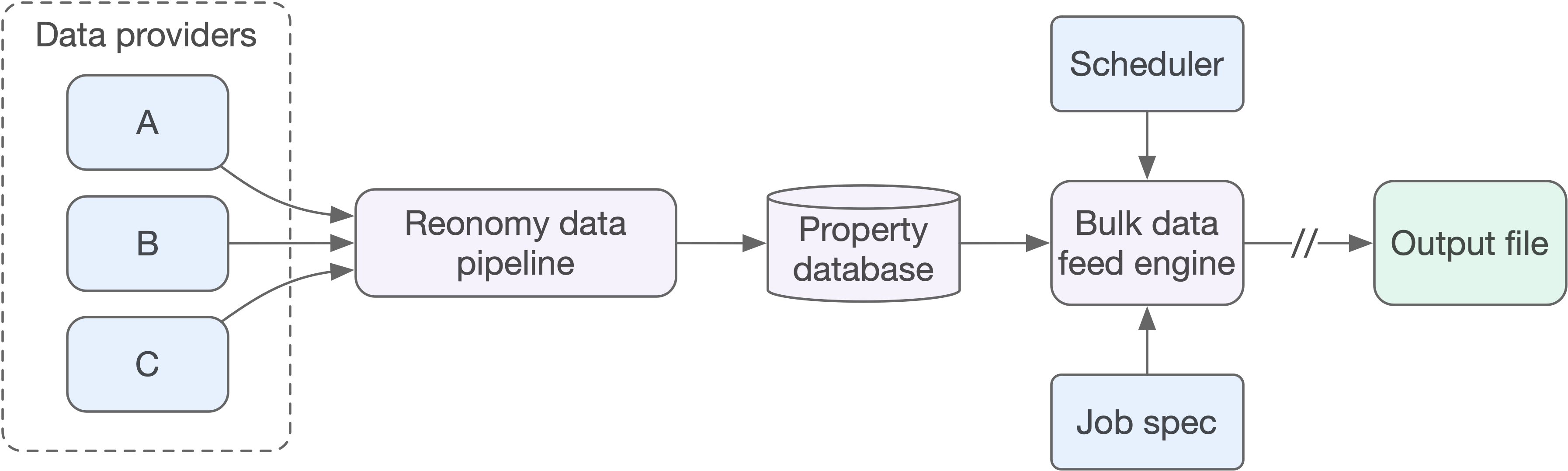
For scheduled runs, we can deliver a full dataset each time, or deliver only those records that have changed since the last run.
By default, a single-file bulk data feed job returns one record for each matching property. For example, if a property search yields 200,000 matching properties, the output file will contain 200,000 records each time you run the job — even if none of the records have changed.
For scheduled bulk data feed jobs, you have the option to receive only records that are new (in other words, records for properties that did not previously meet the search criteria but do now) or have changed. These are known as delta jobs (or incremental jobs). If you run a bulk data feed on a regular basis, configuring it as a delta job can greatly reduce the quantity of data you need to manage and load into your data pipeline or workflow.
The interactive demo on the right simulates a delta run. It contains three steps you can advance through using the button:
Bulk data feeds supports the following output delivery options: